Investigating CockroachDB Performance and Stability with 22k Databases & 300k tables
By Morgan Winslow at
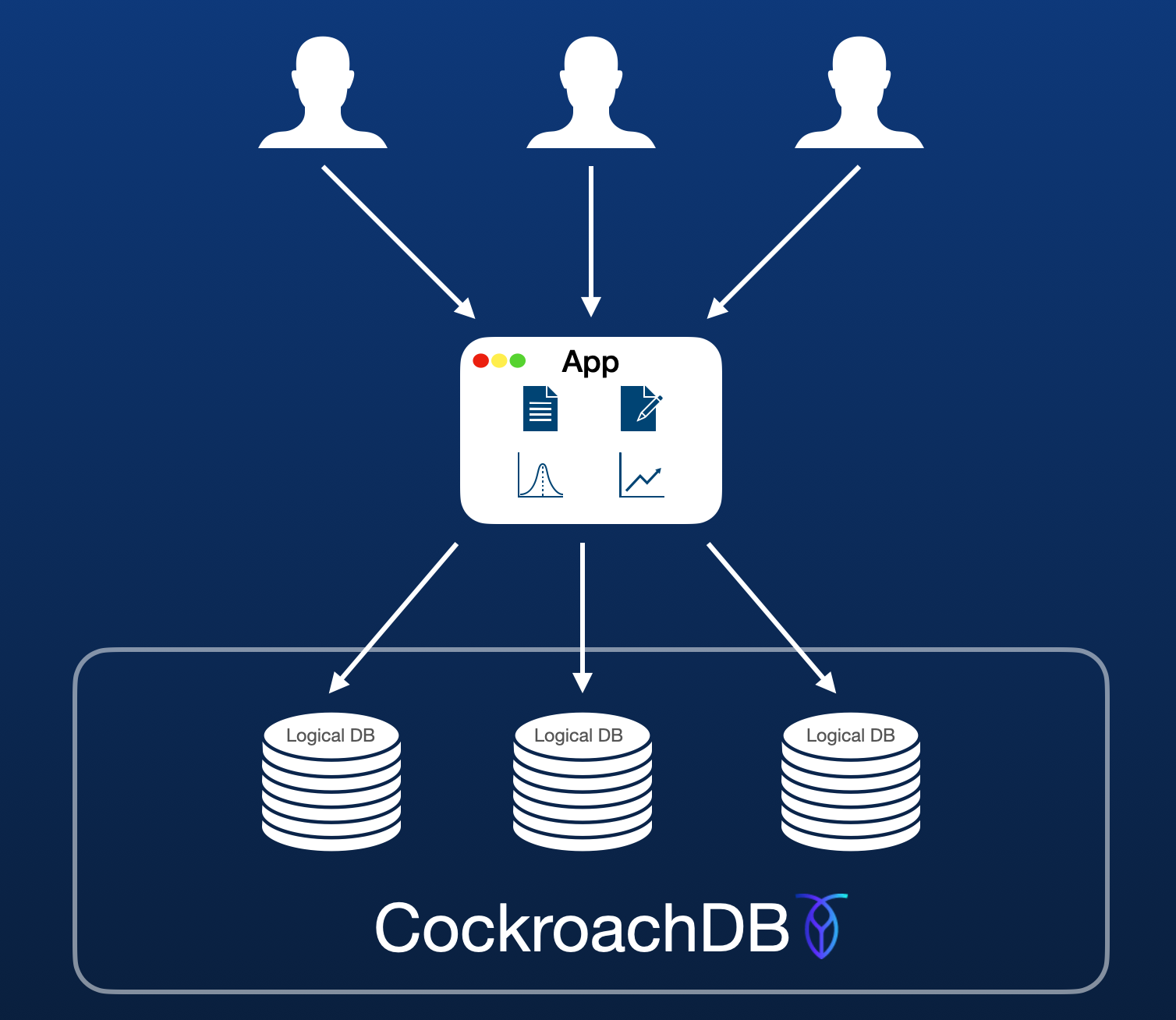
Testing out a "Database per tenant" model in a single CockroachDB cluster
Overview
When it comes to managing multi-tenancy, there's a number of architectural routes you can take. A couple of the most popular are:
- Create a database per tenant
- Use a single database but with tenant IDs to separate out data.
Both of these options have pros and cons, but getting into that is not the intention of this blog. Today we'll be exploring what option 1 may look like on a single CockroachDB cluster.
Is this a sustainable model on CockroachDB? How many databases/tables can we add? I'll attempt to answer these questions and more as I add around 22,000 databases and 300,000 tables to a cluster.
High Level Steps
- Create a 9 node CockroachDB cluster
- Load x instances of the TPC-C database
- Use the built in
cockroach workloadcommand and a script to execute x workloads against x number of databases - Monitor stability and performance throughout the exercise
Set up a CockroachDB Cluster
For this experiment I created a cluster in Google Cloud Platform (GCP) with the below specs.
| Nodes | 9 |
| Region(s) | us-east1 |
| Machine Type | n2-standard-8 |
| vCPU | 8 |
| Memory (GB) | 32 |
| Storage (GB) | 375 |
This I won't be doing a how to on the CockroachDB setup in this blog, but here are some links to get you started. I ended up deploying all my nodes in a single AZ since I wasn't cared about survivability. I also did not create a load balancer in GCP, but rather used HaProxy on the VM I used to run a workload.
Cluster Settings
There's a few cluster settings I enabled to improve performance. The main setting we'll keep throughout the duration of the cluster is:
set cluster setting spanconfig.host_coalesce_adjacent.enabled = true;This setting allows multiple tables per range, rather than a table per range, which can come in handy when adding as many tables as I plan to.
The below settings are only used for initial schema and data load. More can be read about their purpose here.
set cluster setting kv.range_merge.queue_interval = "50ms";
set cluster setting jobs.registry.interval.gc = "30s";
set cluster setting jobs.registry.interval.cancel = "180s";
set cluster setting jobs.retention_time = "15s";Load Databases/Tables
The ultimate goal is to load a lot of databases and tables...but I also want to easily run workloads against those databases once they are in the cluster. The easiest way to accomplish that for me was to leverage one of the built in workloads in CockroachDB.
While there are a number of them available, I chose the tpcc workload since it is a good test of a transactional workload and it can also report back efficiency numbers. Tpcc consists of 9 tables in total. I'd love to see at least 300k tables total, so we have a ways to go.
If you are unfamiliar with TPC-C, more information is available here.
Base workload init Command
The base command for initializing a schema is quite simple with the built in command. It looks like the following, where localhost is ideally a load balancer instead.
cockroach workload init tpcc 'postgresql://root@localhost:26257?sslmode=disable'This command will create 9 tables in a database named tpcc and load 1 warehouse worth of data which comes out to ~200MB. The number of warehouses in configurable via flag, but we'll keep it with the default of 1.
Once the data is compresses & replicated it comes out to around 70MB in CockroachDB. We'll have to keep this number in mind since we currently have 3.1TB of storage available. The final database result for 1 warehouse looks like this.
| schema_name | table_name | type | owner | estimated_row_count |
|---|---|---|---|---|
| public | customer | table | root | 30000 |
| public | district | table | root | 10 |
| public | history | table | root | 30000 |
| public | item | table | root | 100000 |
| public | new_order | table | root | 9000 |
| public | order | table | root | 30000 |
| public | order_line | table | root | 300343 |
| public | stock | table | root | 100000 |
| public | warehouse | table | root | 1 |
Expanding Base Command
There's a few things we need to do to expand on the base command. The first one should be obvious...we can't use the name tpcc if we are loading tens of thousands of databases 😄
Depending on how much time you have, this second tip may be equally important. The workload init command does an INSERT by default. While this is ok and may be something you want to test, I'd like to switch to IMPORT and make things a bit faster.
With these two thoughts in mind, our base command now looks something more like this:
cockroach workload init tpcc --db database_$i --data-loader import 'postgresql://root@localhost:26257?sslmode=disable'Throw in a Bash Script
You'll notice the command above specifies database_$i since we want to load i instances. Feel free to get as fancy as you want here with your scripting abilities, but in it's simplest form we can do something like the following.
#!/usr/bin/env bash
for i in {1..20000}
do
cockroach workload init tpcc --db test$i --data-loader import 'postgresql://root@localhost:26257?sslmode=disable'
doneThis will admittedly take a while as we are loading 20,000 databases, 180,000 tables, and ~1.5TB of data (after compression). As I said, feel free to write a more impressive script to parallelize this logic and speed up the process.
Bonus - Speed up via a Backup/Restore
If you want to speed up past the IMPORT command, you can leverage a BACKUP and RESTORE process that I found to be even quicker.
Backup a tpcc database into cloud storage. This example shows s3, but other cloud storage options are available as well. These commands are run once actually in the SQL shell.
BACKUP DATABASE tpcc INTO 's3://{BUCKET NAME}?AWS_ACCESS_KEY_ID={KEY ID}&AWS_SECRET_ACCESS_KEY={SECRET ACCESS KEY}' AS OF SYSTEM TIME '-10s';Restore the tpcc database into a new database with a different name.
RESTORE DATABASE tpcc FROM LATEST IN 's3://{bucket_name}?AWS_ACCESS_KEY_ID={key_id}&AWS_SECRET_ACCESS_KEY={access_key}' WITH DETACHED, new_db_name = 'database_$i';We could also loop through this command in the language of our choice achieve a bit quicker results than the IMPORT.
Adding Additional Tables - No Data
As I mentioned above, 20k iterations only gets us to 180k tables. I'd like to get closer to 300k tables managed, but I'm not super interested in adding more data as we are already at 50% capacity.
At this point I added ~700 more databases, each with 150 tables. This schema was quite different than the tpcc tables already loaded. How, or if, you chose to get to this higher number of tables I'll leave up to you.
Proof
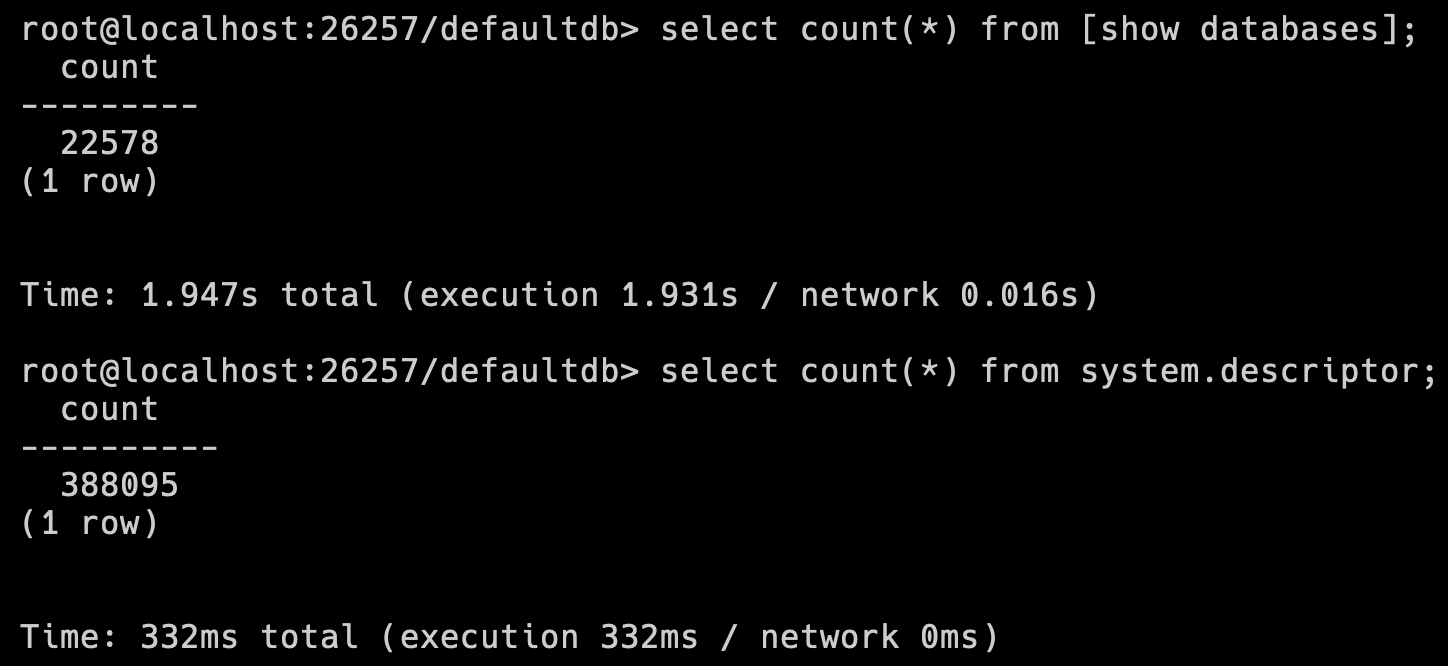
Just a quick confirmation of the cluster size and items added!
First we'll see the total databases count is just over 22.5k. Then we'll do a count on the descriptors. Descriptors include tables, among a few other things.
Here is the Cluster Overview.

Running a Workload
Now that we have everything loaded, we can go through a similar process to run workloads against some of these identical databases. While I don't have the infrastructure in place to run 22.5k concurrent tpcc workloads...hopefully I can get something decent going.
Base workload run Command
Just as the initial load, Cockroach makes actually running the load simple as well. The example below will run a tpcc workload for 60 minutes.
cockroach workload run tpcc --duration=60m 'postgresql://root@localhost:26257?sslmode=disable'Expanding the Base Command
There's a few modifications I made here as well which ends up being pretty similar to the initial load.
cockroach workload run tpcc --db database_$i --duration=60m --conns=1 --display-every=1m 'postgres://root@10.142.0.2:26257?sslmode=disable'Once again we've added a database flag so we can select some of the databases we created. I also added a connections flag and set it to 1. By default, the workload will create 2 connections per run.
Lastly I added a --display-every flag. This just changes how often the workload prints out it's per operation statistics. The default is 1s and prints out quite a lot. I wasn't really planning on digesting all this information for 500+ workloads. Later on we will grab the final workload statistics which are printed out at the end.
Throw in a Bash Script
Now that we have our base command, we can create another script to loop through and start these processes. I used a separate virtual machine, outside of the cluster, and with HaProxy installed. FYI, lower these numbers quite a bit if you don't have a solid VM. I was using n2-standard-32.
Below is the simple script I used that loops through starting the workload 500 times.
#!/usr/bin/env bash
for i in {1..500}
do
nohup cockroach workload run tpcc --db database_$i --duration=60m --conns=1 --display-every=1m 'postgres://root@localhost:26257?sslmode=disable' > results/$i.txt 2>&1 &
doneThe code at the end throws the output of each workload into it's own file inside a /results folder.
For my actual tests, I leveraged the following syntax so I wasn't always selecting just the first 500. (I realize there's a semi decent chance for dupes with this logic)
nohup cockroach workload run tpcc --db database_$(( ( RANDOM % 20000 ) + 1 )) --conns=1Results
Below are the results for workloads of sizes 500, 750, and 1000. Each ran for 1 hour.
| Workloads | CPU Usage | QPS | P99 Latency | Tpcc Efc (avg) |
|---|---|---|---|---|
| 500 | ~25-50% | ~1,800/s | ~50ms | 97% |
| 750 | ~25-50% | ~2,200/s | ~58ms | 97% |
| 1000 | ~45-60% | ~3,300/s | ~70ms (w/ spikes) | 97% |
Conclusion and Next Steps
Overall I thought CockroachDB handled these tests well while maintaining a tpcc efc percentage of 97% throughout all tests. Mileage will vary depending on number of nodes and vCPU, but this could be a viable option if the current solution today is creating a physical database per tenant.
There's a few things I'd expand on when testing out this model more:
- Impact and speed of making a schema change across each database
- Implementing role based access to each database
- QPS against a non tpcc workload
- Even more tables! Although not mentioned in the blog, I did test 200k vs 300k and saw no differences in performance.